ETL¶
The Carrot ETL process runs via a Command Line Interface, installed with the carrot-cdm package.
In the context of the Carrot workflow ETL stands for (and means):
- Extract: input data is extracted into
.csvformat and (optionally) pseudonymised - Transform: a CDM model is created and processed, given the extracted data and a
jsontransformation rules file which tells the software how to map (transform) the data. - Load: inserts the data into a database or other destination.
Workflow¶
Our ETL workflow is provided in the form of the so-called ETL-Tool which is a command line interface (CLI):
carrot etl --help
Usage: carrot etl [OPTIONS] COMMAND [ARGS]...
Command group for running the full ETL of a dataset
Options:
--config, --config-file TEXT specify a yaml configuration file
-d, --daemon run the ETL as a daemon process
-l, --log-file TEXT specify the log file to write to
--help Show this message and exit.
This is an automated tool, meaning it is able to run (optionally as a background process) and detect changes in the inputs or configuration files to process new data dumps.
Currently, automation using the carrot etl CLI is possible for loading to a BC-Link or outputing to a local file storage system.
Carrot--BC-LINK Workflow¶
The whole point in transforming data into the OMOP CDM format is so the data can be uploaded to BC-Link. This workflow can be performed in one step with the correct configuration of the input yaml file when running carrot etl --config <yaml file>, see:
However, the process may need to be decoupled into multiple steps; for example, if BC-Link is not hosted on a machine that has access to the original data. In this scenario the carrot etl or carrot run map can be used to perform the transform (OMOP mapping), the output files can then be transferred to the machine hosting BC-Link and be uploaded (from the command-line, or using the BC-Link GUI)
Architecture Overview¶
A schematic diagram of the Carrot/bclink ETL is given below:
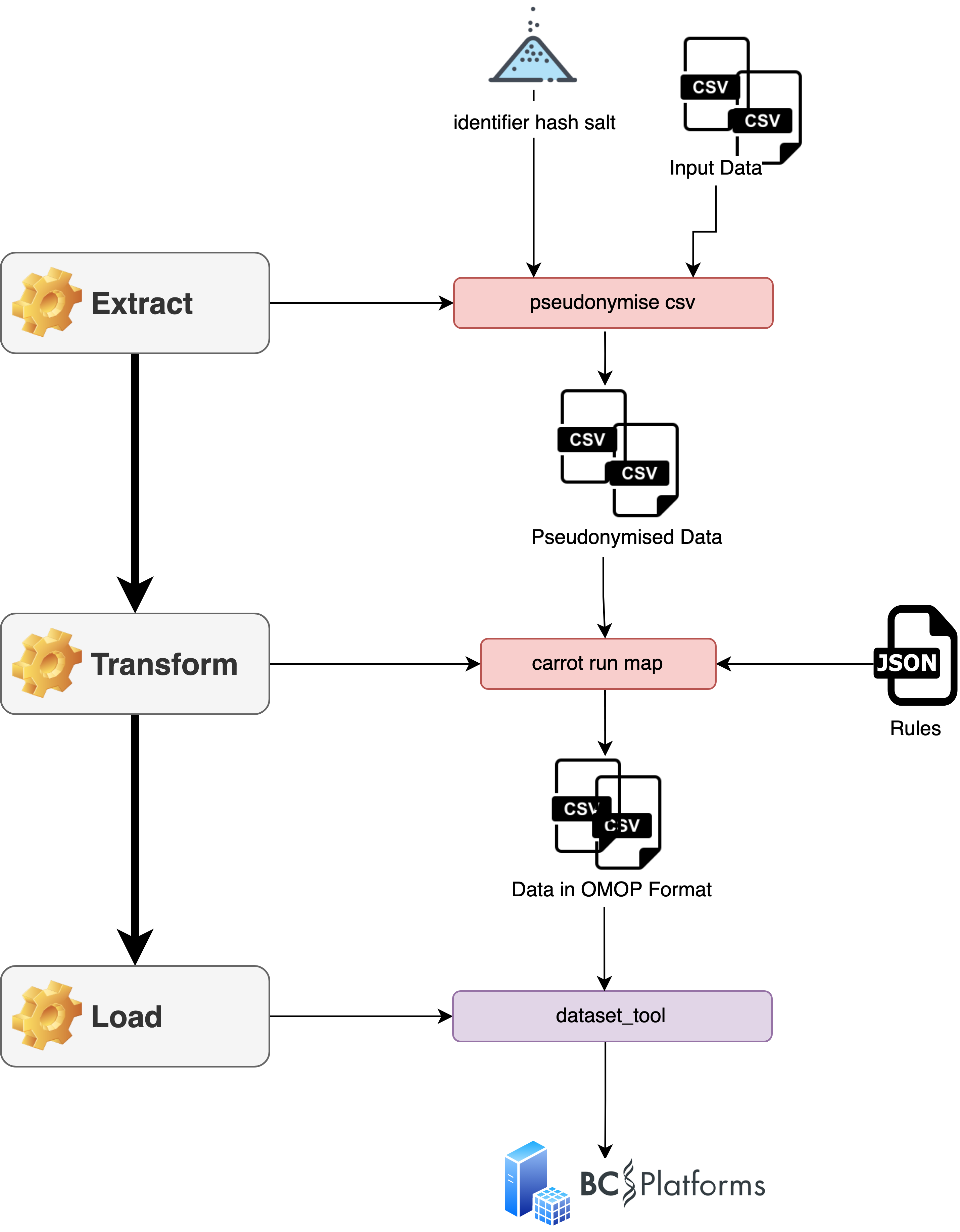
The following breaks down what each part of the process is doing...
Extract¶
- Formats the input data to abide by the co-connect data-standards [manual]
- Creates data-dumps of the input datasets in the form of
csvfiles for each dataset table. [manual] - Pseudonymises the input datasets, masking any person identifiers or person IDs [optionally automated]
Transform¶
-
The transform mapping is executed with the command
carrot run map [arguments], where additional arguments pass the paths to a mapping-rulesjsonfile and input datacsvfiles [optionally automated]:- A new pythonic
CommonDataModelis created. DataCollectionis created to handle/chunk the input files and is added to theCommonDataModel.- The mapping-rules
jsonis used to create new CDM Tables (e.g. Person).- For each CDM Table, multiple tables can be created. E.g. there may be multiple Condition Occurrences defined across multiple input data files and columns (fields).
- The rules
jsonencodes so-called "term-mapping" - how to map raw values into OHDSI concept IDs for the output. These are setup as lambda functions and passed to the object'sdefinefunction
- Processing of the
CommonDataModelis triggered:- [optionally chunked] A new chunk of
DataCollectionis grabbed. - Each CDM table is looped over:
- All objects of this CDM table are found and looped over:
- The
definefunction is called to apply the rules. - A new dataframe is retrieved for the object.
- The
- All objects of this CDM table are found and looped over:
- All retrieved dataframes are merged.
- The merged dataframe is has a formatting check applied
- The merged dataframe primary keys are correctly indexed
- The final dataframe is saved/appended to an output
tsvfile. - This is repeated until all chunks are processed.
- [optionally chunked] A new chunk of
- A new pythonic
Loads¶
- Uploads the output
tsvfiles into the bclink job-queue which formats and uploads these into the bclink database [optionally automated]